Project Overview
Accurate prediction of breast cancer outcomes can support better treatment decisions. This project explored how machine learning can be applied to clinical datasets with missing values and variable quality.
The Problem
Clinical datasets are often incomplete, heterogeneous, and difficult to use directly. The challenge was to build a reliable predictive workflow despite data quality limitations.
Approach
- Preprocessed clinical variables and handled missing data
- Built and evaluated classification models
- Compared model behavior and focused on reliability
- Worked toward better specificity, not just raw accuracy
Results
- Reached approximately 81% accuracy
- Improved specificity by 20% with earlier baseline behavior
Visual Insights
Model Performance
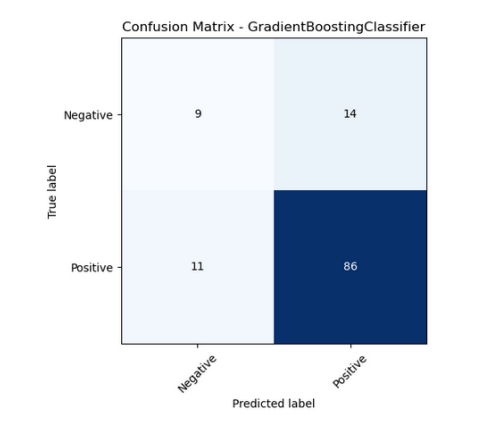
This model predicts chemotherapy response using clinical data. Despite data limitations, it achieves strong classification performance, showing the potential of machine learning in supporting treatment decisions.
Data Imputation Analysis
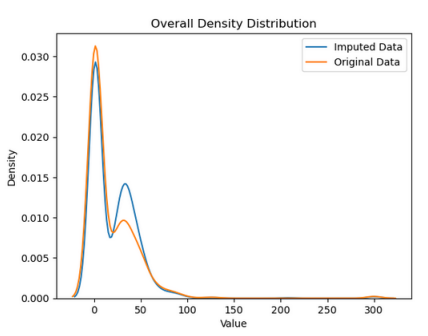
Clinical datasets contain significant missing data. This comparison shows how imputation methods preserve the original data distribution, enabling more reliable modeling.
Challenges
- Missing and inconsistent patient data
- Limited dataset size
- Balancing model performance with interpretability
Next Steps
- Use larger and more diverse datasets
- Strengthen validation workflow
- Move toward decision support applications in healthcare settings